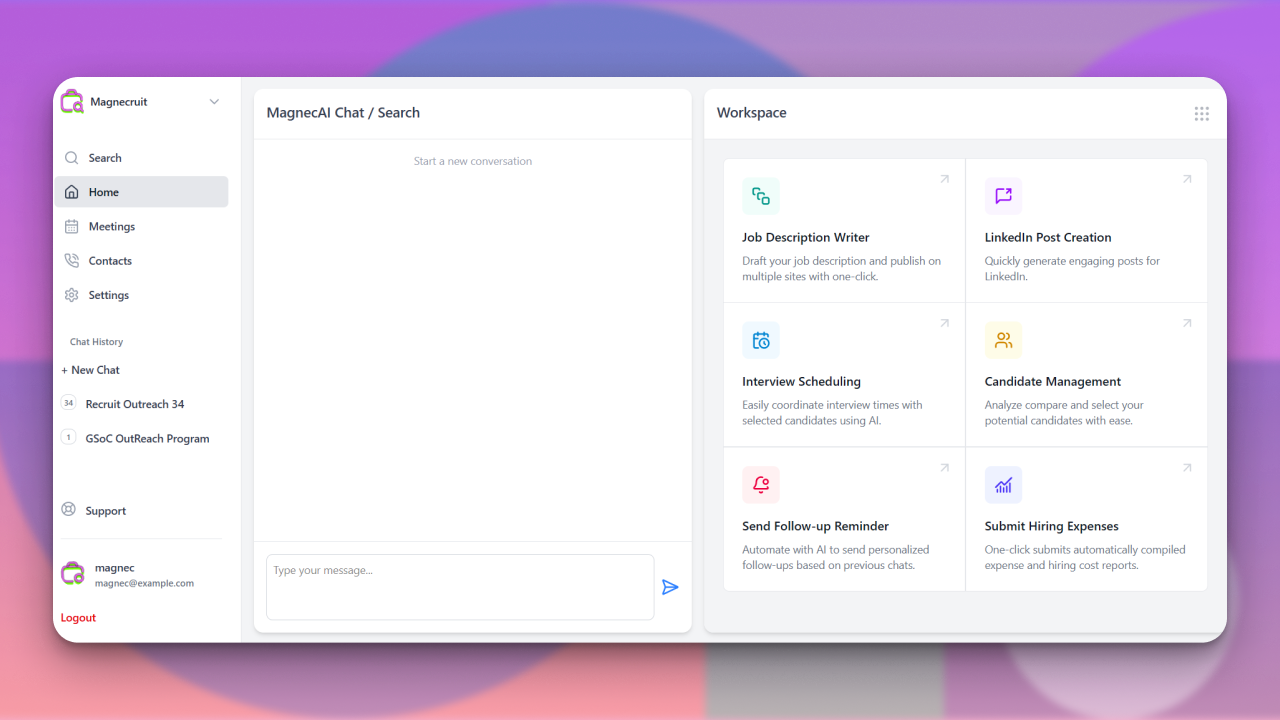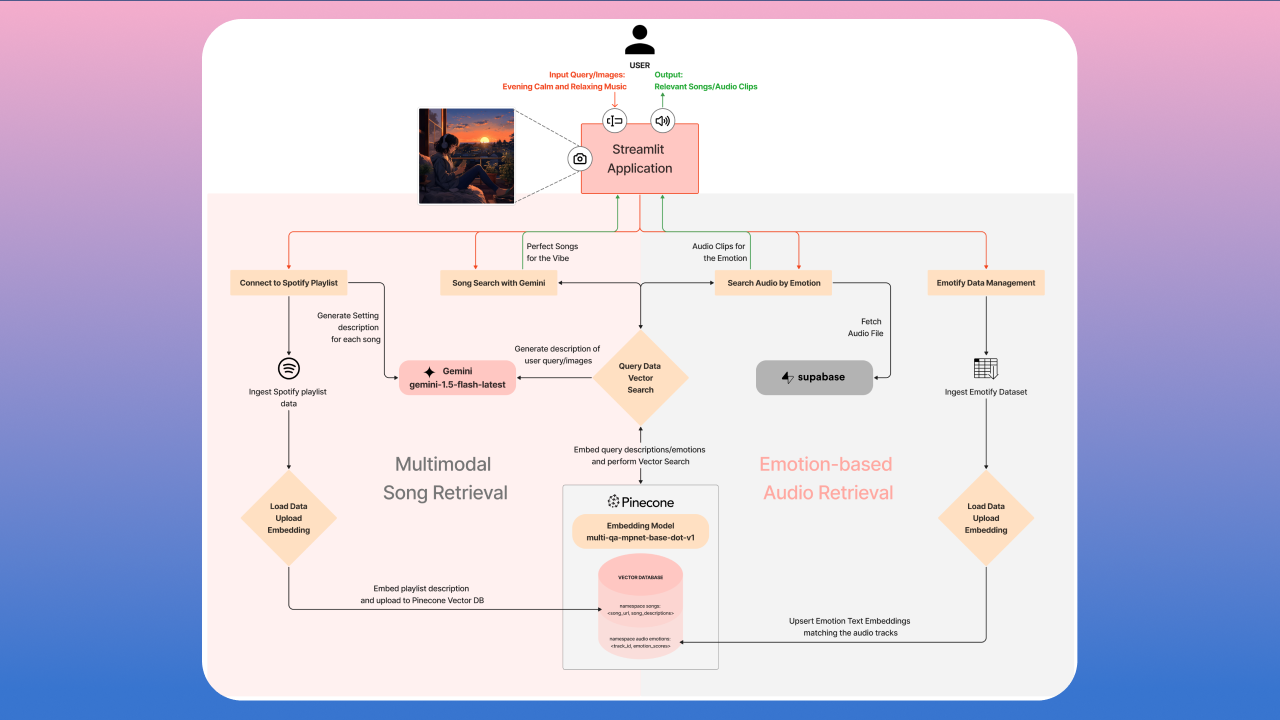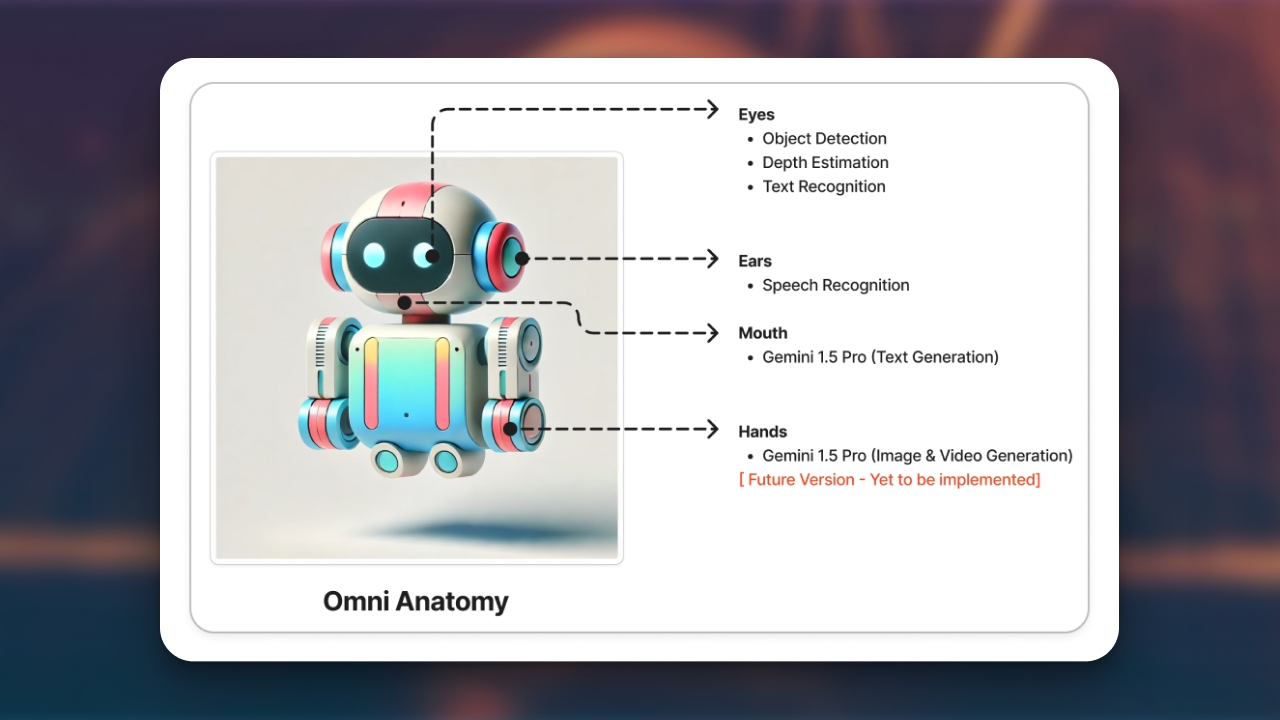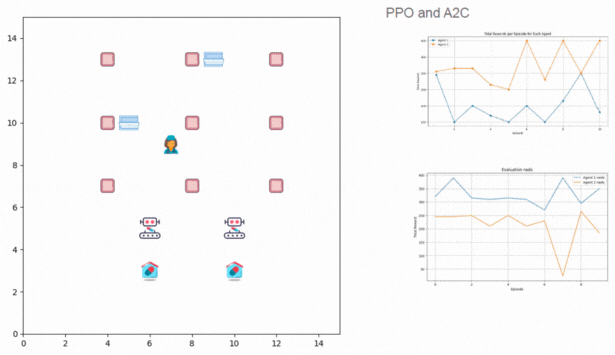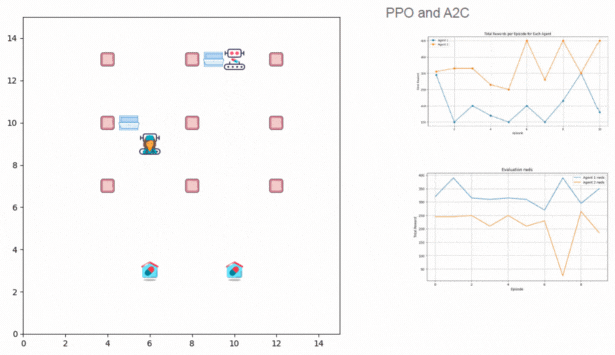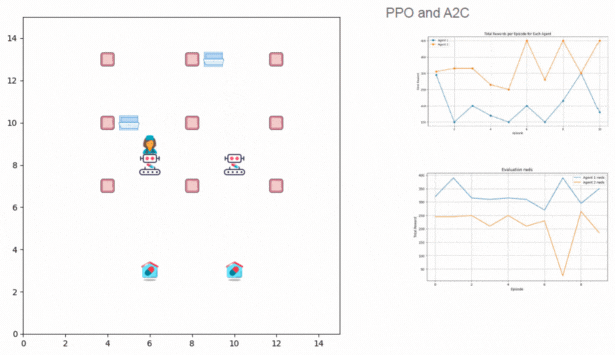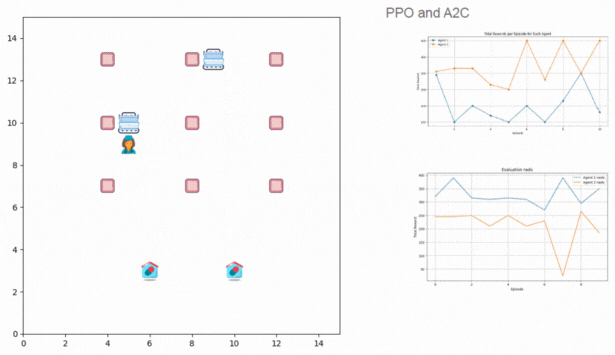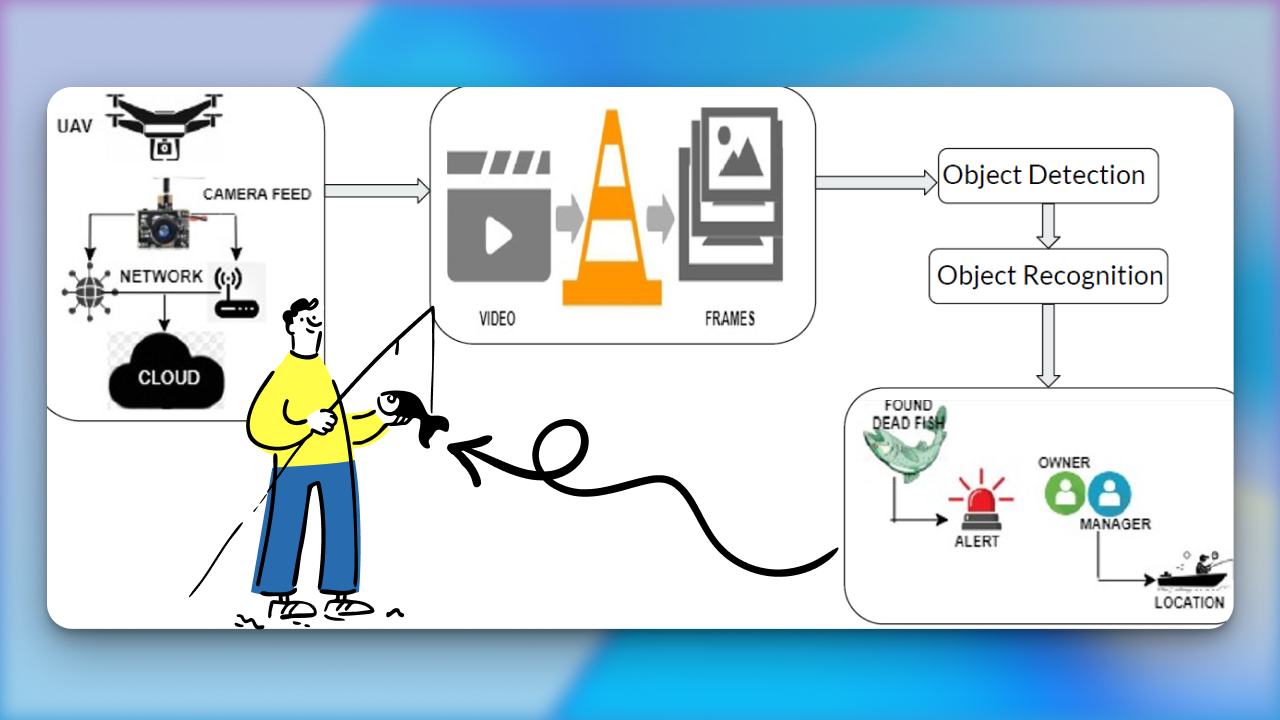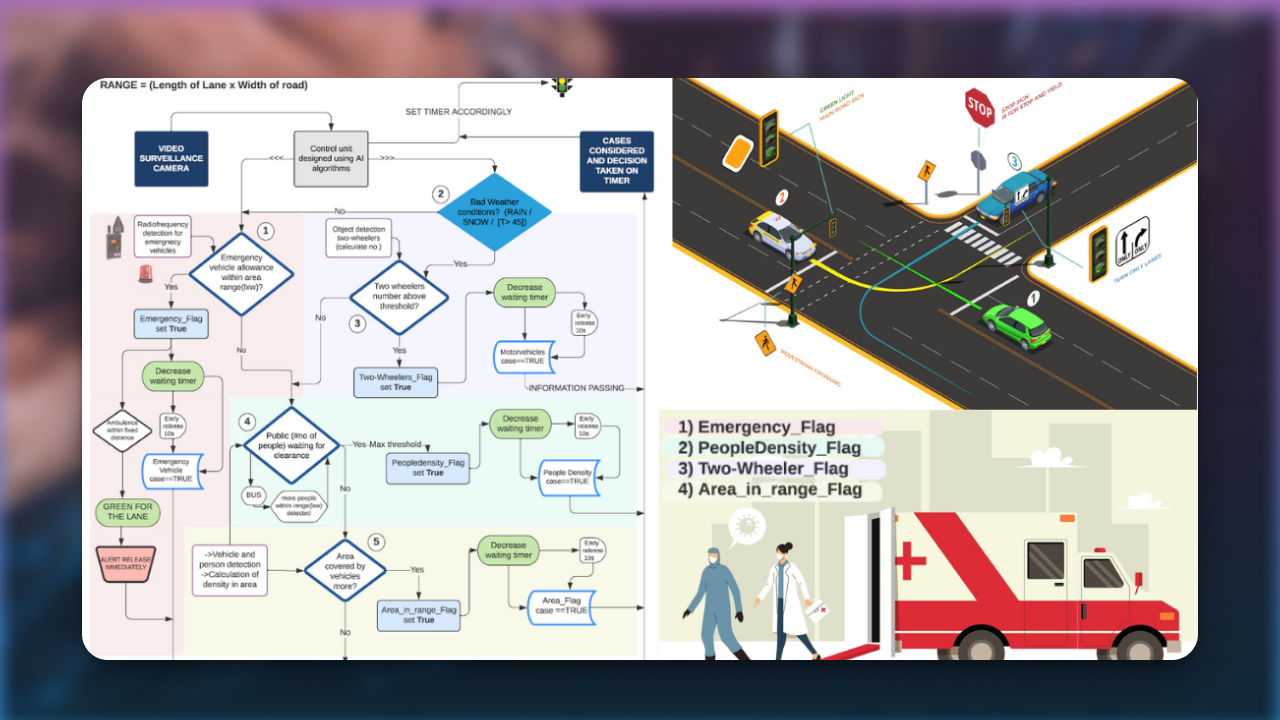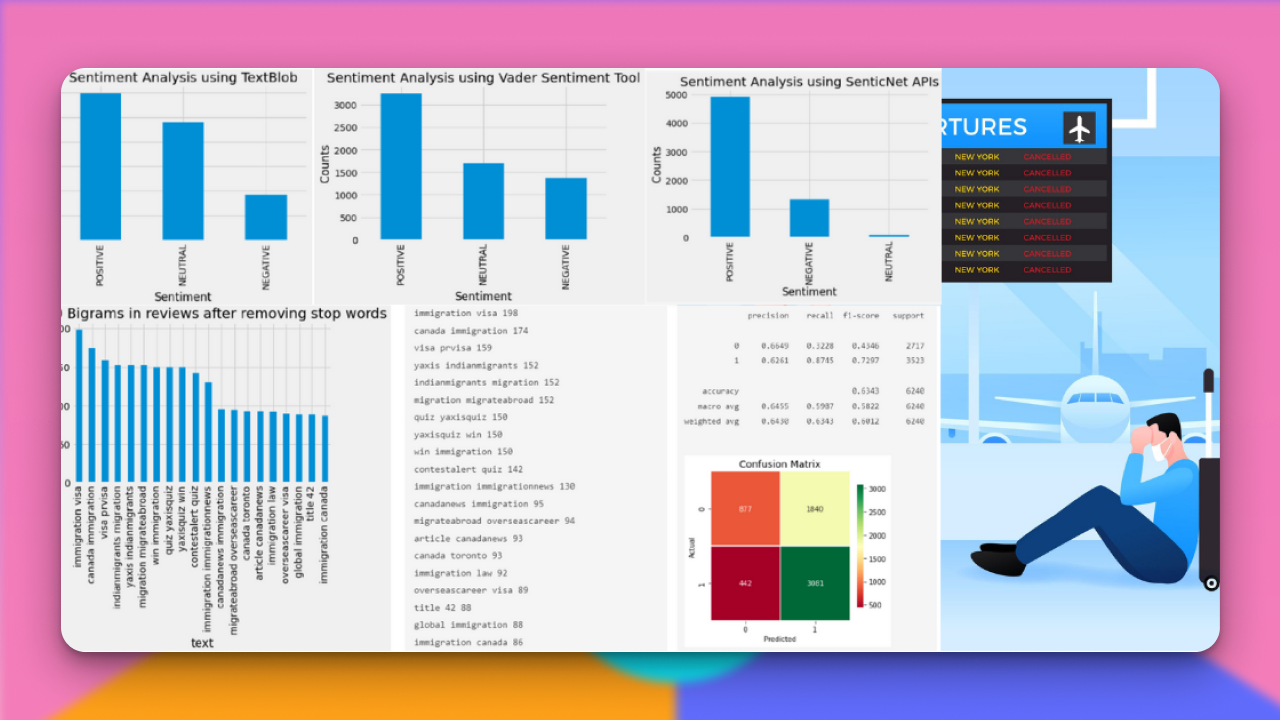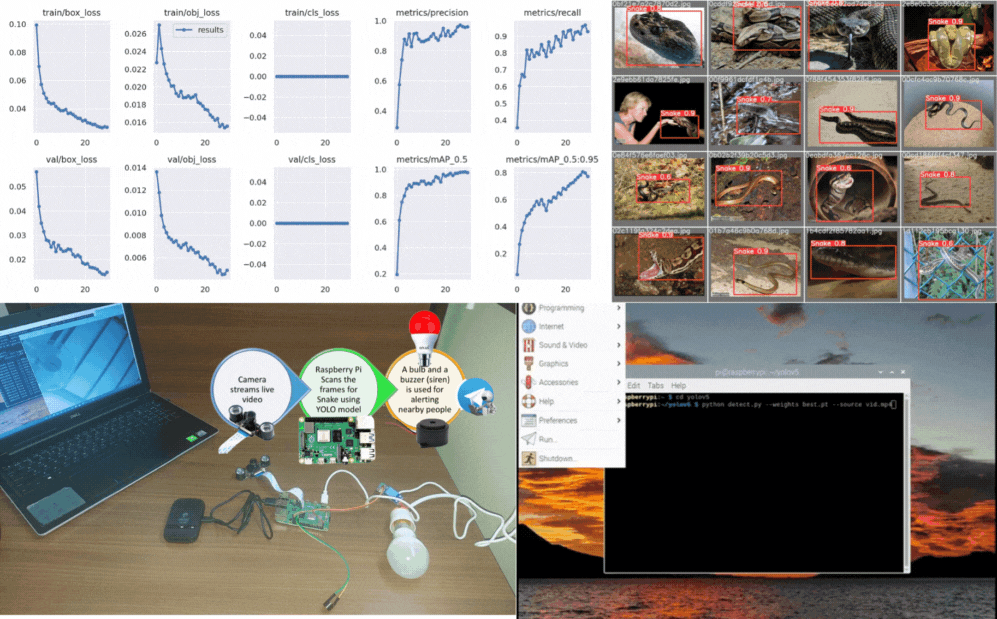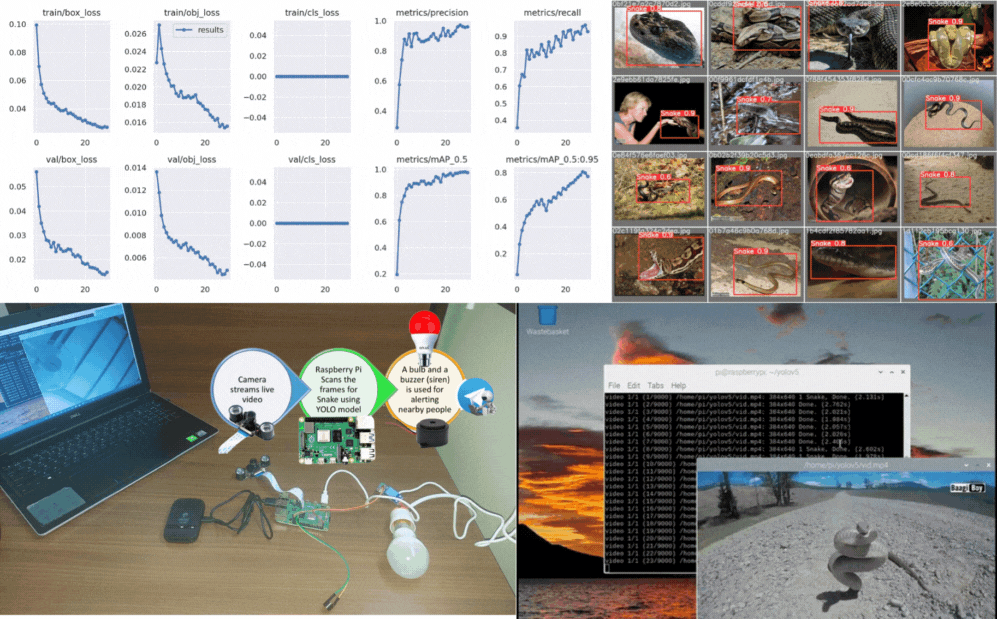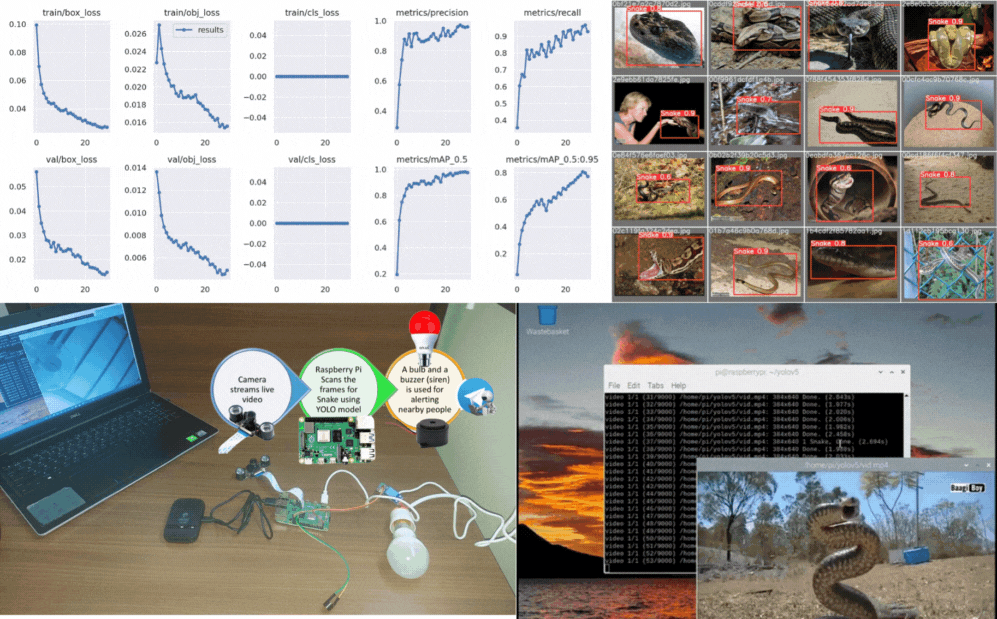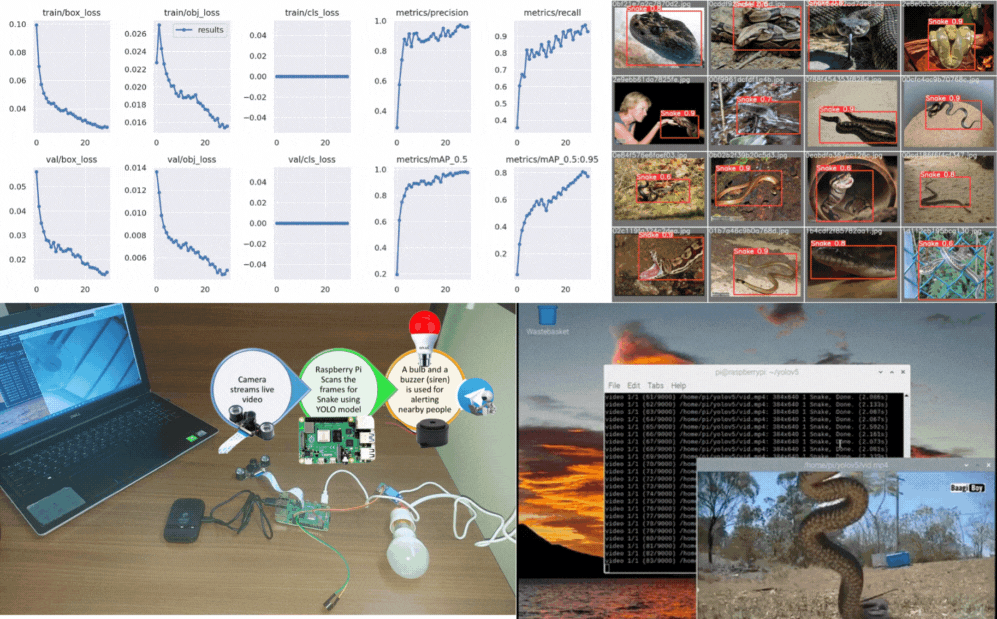
PaliGemma: Multimodal Vision-Language Model from Scratch
RecentAI/MLGenerative AIHighlights
05/2025 - 05/2025
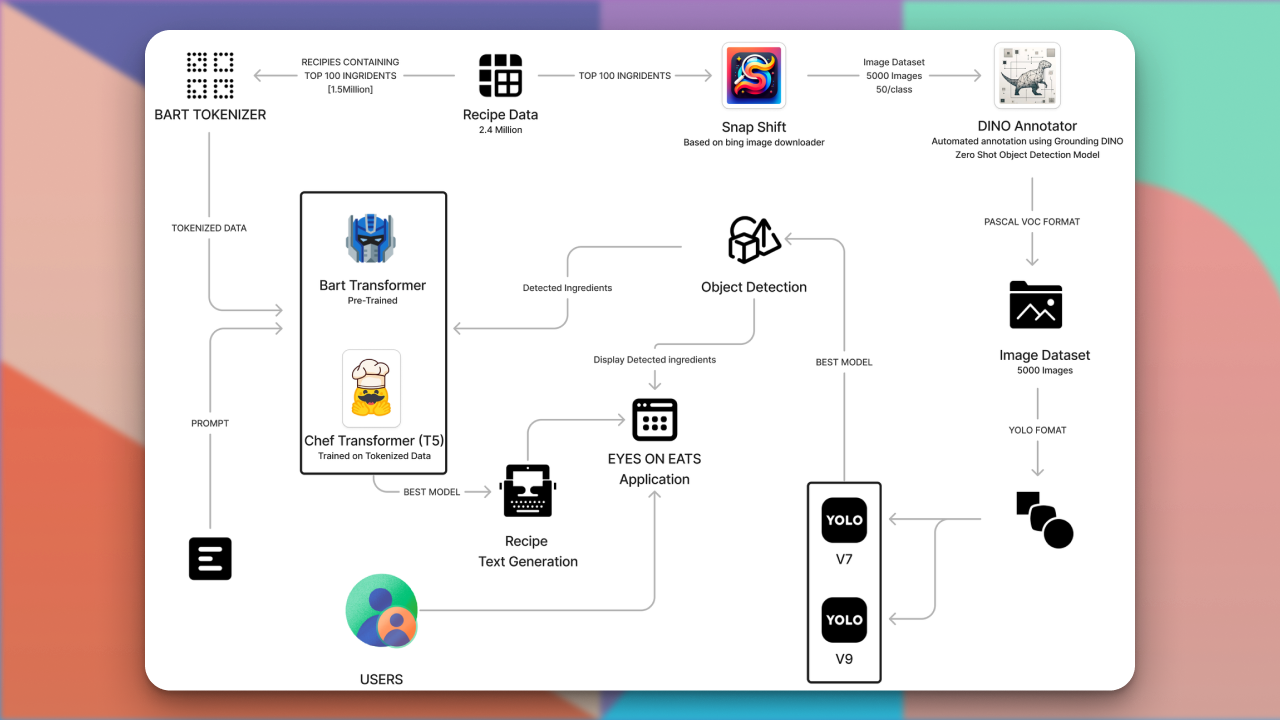
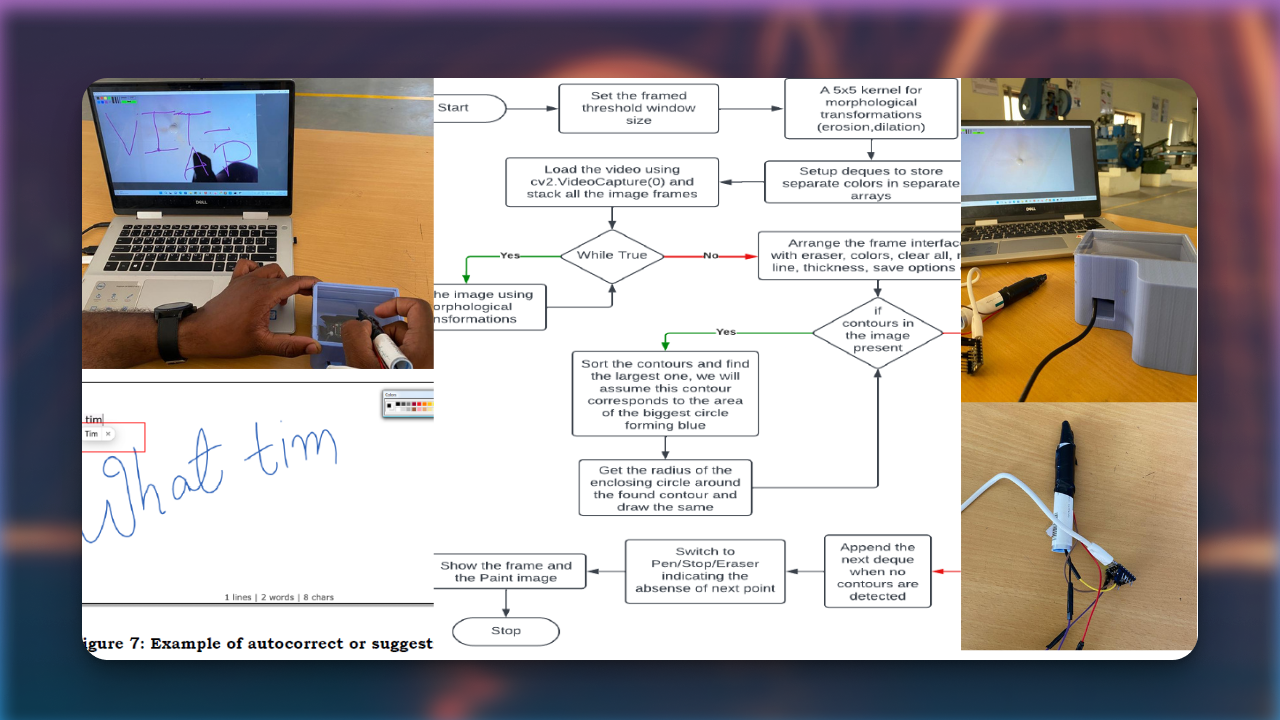
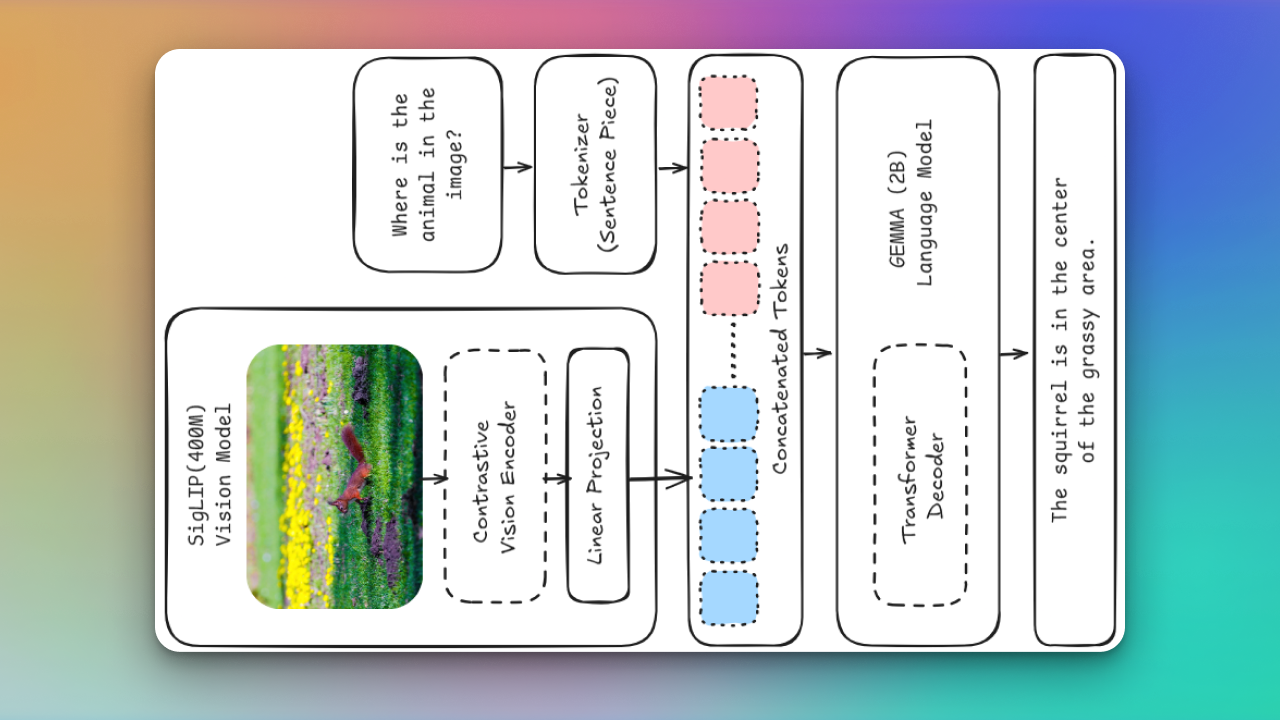
Recreated PaliGemma from scratch to deeply understand vision-language model components like SigLIP, Gemma, KV cache, attention types, contrastive learning, rotary embeddings, and multimodal inference architecture.
Key Skills: Vision-Language Models, Contrastive Learning, Rotary Embeddings, KV Cache, Multimodal Inference, PyTorch, Transformer Architectures, SigLIP, Gemma
Learn more